ro.sync.ecss.extensions.api
Interface AuthorDocumentController
@API(type=NOT_EXTENDABLE,
src=PUBLIC)
public interface AuthorDocumentController
Provides methods for modifying the Author document.
|
Method Summary |
void |
addAuthorListener(AuthorListener listener)
Add an Author listener to be notified about changes regarding the document
and the document structure. |
void |
addAuthorPersistentHighlightListener(AuthorPersistentHighlightsListener listener)
Adds a listener to be notified about changes regarding the persistent
highlights. |
void |
addClipboardFragmentProcessor(ClipboardFragmentProcessor clipboardFragmentProcessor)
Add a processor which can analyze and modify AuthorDocumentFragment objects before they are inserted in the Author. |
void |
addUniqueAttributesProcessor(UniqueAttributesProcessor uniqueAttributesProcessor)
Add a processor which is asked to automatically generate unique IDs after content has been inserted in the Author. |
void |
beginCompoundEdit()
Begin a compound edit. |
void |
cancelCompoundEdit()
Cancel the current compound edit. |
AuthorDocumentFragment |
createDocumentFragment(AuthorNode node,
boolean copyContent)
Create a document fragment containing a copy of the node. |
AuthorDocumentFragment |
createDocumentFragment(int startOffset,
int endOffset)
Create an Author content fragment containing a clone of the document content for the
given range of offsets. |
AuthorDocumentFragment |
createNewDocumentFragmentInContext(java.lang.String xmlFragment,
int contentOffset)
Create a new AuthorDocumentFragment from an XML string in a specified context. |
AuthorDocumentFragment[] |
createNewDocumentFragmentsInContext(java.lang.String[] xmlFragments,
int[] contentOffsets)
Create an array of AuthorDocumentFragment from an array of XML strings
in specified contexts. |
AuthorDocumentFragment |
createNewDocumentTextFragment(java.lang.String textFragment)
Create a new AuthorDocumentFragment from an string. |
javax.swing.text.Position |
createPositionInContent(int offset)
Create a flexible position in the Author Content. |
boolean |
delete(int startOffset,
int endOffset)
Deletes a document fragment between the start and end offset. |
boolean |
deleteNode(AuthorNode node)
Delete a node. |
void |
endCompoundEdit()
End a compound edit. |
java.lang.Object[] |
evaluateXPath(java.lang.String xpathExpression,
AuthorNode contextNode,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments,
boolean processChangeMarkers)
Evaluates an XPath expression. |
java.lang.Object[] |
evaluateXPath(java.lang.String xpathExpression,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments)
Evaluates an XPath expression. |
java.lang.Object[] |
evaluateXPath(java.lang.String xpathExpression,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments,
boolean processChangeMarkers)
Evaluates an XPath expression. |
AuthorNode[] |
findNodesByXPath(java.lang.String xpathExpression,
AuthorNode contextNode,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments,
boolean processChangeMarkers)
Finds the author nodes selected by the given XPath expression. |
AuthorNode[] |
findNodesByXPath(java.lang.String xpathExpression,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments)
Finds the author nodes selected by the given XPath expression. |
AuthorNode[] |
findNodesByXPath(java.lang.String xpathExpression,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments,
boolean processChangeMarkers)
Finds the author nodes selected by the given XPath expression. |
AuthorDocument |
getAuthorDocumentNode()
Returns the edited author document. |
AuthorSchemaManager |
getAuthorSchemaManager()
|
void |
getChars(int where,
int len,
javax.swing.text.Segment chars)
The content represents the entire text content of the Author page + additional markers/sentinels
at offsets which are pointed to by the AuthorNodes. |
AuthorNode |
getCommonParentNode(AuthorDocument doc,
int startOffset,
int endOffset)
Find the common ancestor node of the two offsets. |
OffsetInformation |
getContentInformationAtOffset(int offset)
Returns content information for the offset. |
AuthorDocumentType |
getDoctype()
Returns information about the internal associated document type. |
AuthorFilteredContent |
getFilteredContent(int start,
int end,
AuthorNodesFilter nodesFilter)
Retrieves the content between the given start and end offset, excluding the
content of the invisible nodes (that have display none style property), the
content deleted with track changes, the sentinels of inline elements and the
content of filtered nodes. |
AuthorNode |
getNodeAtOffset(int offset)
Returns the node at the given offset. |
java.lang.String |
getText(int offset,
int length)
Deprecated. Use the API based on the AuthorNode to get only the displayed text
without mark-up markers. |
TextContentIterator |
getTextContentIterator(int startOffset,
int endOffset)
Get an iterator over the text content between two offsets. |
int |
getTextContentLength()
Deprecated. Use the API based on the AuthorNode to get the length
of the displayed text only, without mark-up markers. |
javax.swing.undo.UndoManager |
getUndoManager()
Get access to the Author undo manager. |
java.lang.String |
getUnparsedEntityUri(AuthorNode contextNode,
java.lang.String entityName)
Returns the URI of the unparsed entity with the specified name, in the
same document as the context node. |
int |
getXPathLocationOffset(java.lang.String xpathLocation,
java.lang.String relativePosition)
Compute the document offset defined by the XPath location and relative position. |
boolean |
inInlineContext(int offset)
Test if the context at the given offset is inline or not. |
void |
insertFragment(int insertOffset,
AuthorDocumentFragment frag)
Insert an AuthorDocumentFragment at the given offset. |
SchemaAwareHandlerResult |
insertFragmentSchemaAware(int insertOffset,
AuthorDocumentFragment frag)
Insert an AuthorDocumentFragment at the given offset in schema aware mode. |
void |
insertMultipleElements(AuthorElement parentElement,
java.lang.String[] elementNames,
int[] offsets,
java.lang.String namespace)
Insert multiple elements at the given offsets. |
boolean |
insertMultipleFragments(AuthorElement parentElement,
AuthorDocumentFragment[] fragments,
int[] offsets)
Insert multiple fragments at the given offsets. |
void |
insertText(int offset,
java.lang.String text)
Inserts a text at the given offset. |
void |
insertXMLFragment(java.lang.String xmlFragment,
AuthorNode relativeTo,
java.lang.String relativePosition)
Insert an XML fragment relative to the given node and according with the relativePosition. |
void |
insertXMLFragment(java.lang.String xmlFragment,
int offset)
Insert an XML fragment at the given offset. |
void |
insertXMLFragment(java.lang.String xmlFragment,
java.lang.String xpathLocation,
java.lang.String relativePosition)
Insert an XML fragment relative to the node identified by the xpathLocation
and according with the relativePosition. |
SchemaAwareHandlerResult |
insertXMLFragmentSchemaAware(java.lang.String xmlFragment,
int offset)
Insert an XML fragment at the given offset in schema aware mode. |
SchemaAwareHandlerResult |
insertXMLFragmentSchemaAware(java.lang.String xmlFragment,
int offset,
boolean replaceSelection)
Insert an XML fragment at the given offset in schema aware mode. |
SchemaAwareHandlerResult |
insertXMLFragmentSchemaAware(java.lang.String xmlFragment,
java.lang.String xpathLocation,
java.lang.String relativePosition)
Insert an XML fragment relative to the node identified by the xpathLocation
and according with the relativePosition. |
boolean |
isEditable(AuthorNode node)
Test if a node is editable or not. |
void |
multipleDelete(AuthorElement parentElement,
int[] startOffsets,
int[] endOffsets)
Deletes the given intervals. |
boolean |
processContentRange(int startOffset,
int endOffset,
RangeProcessor rangeProcessor)
This method is useful if you want to make text processing on a given Author selection. |
void |
removeAttribute(java.lang.String attributeName,
AuthorElement element)
Removes an attribute from the given element. |
void |
removeAuthorListener(AuthorListener listener)
Remove an Author listener. |
void |
removeAuthorPersistentHighlightListener(AuthorPersistentHighlightsListener listener)
Removes a persistent highlights listener. |
void |
removeClipboardFragmentProcessor(ClipboardFragmentProcessor clipboardFragmentProcessor)
Remove a processor which can analyze and modify AuthorDocumentFragment objects before they are inserted in the Author. |
void |
removeUniqueAttributesProcessor(UniqueAttributesProcessor uniqueAttributesProcessor)
Remove a processor which is asked to automatically generate unique IDs after content has been inserted in the Author. |
void |
renameElement(AuthorElement contextNode,
java.lang.String newName)
Rename an Author Element, set another qualified name to it. |
void |
replaceRoot(AuthorDocumentFragment fragment)
Replace the current root element with the new given one. |
java.lang.String |
serializeFragmentToXML(AuthorDocumentFragment fragment)
Takes the given fragment and serializes it to XML text in the context
of the current document. |
void |
setAttribute(java.lang.String attributeName,
AttrValue value,
AuthorElement element)
Sets the value of an attribute in the specified element. |
void |
setDoctype(AuthorDocumentType docType)
Set a new internal document type to the Author content. |
void |
setDocumentFilter(AuthorDocumentFilter authorDocumentFilter)
Sets the AuthorDocumentFilter to be used for altering the document edits. |
void |
surroundInFragment(AuthorDocumentFragment xmlFragment,
int startOffset,
int endOffset)
Surround the content between the given offsets with the xmlFragment. |
void |
surroundInFragment(java.lang.String xmlFragment,
int startOffset,
int endOffset)
Surround the content between the given offsets with the xmlFragment. |
void |
surroundInText(java.lang.String header,
java.lang.String footer,
int startOffset,
int endOffset)
Surround the content between the given offsets with plain text fragments(without XML parsing). |
AuthorDocumentFragment |
unwrapDocumentFragment(AuthorDocumentFragment fragmentToUnwrap)
Unwrap a given Author document fragment. |
delete
boolean delete(int startOffset,
int endOffset)
- Deletes a document fragment between the start and end offset.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
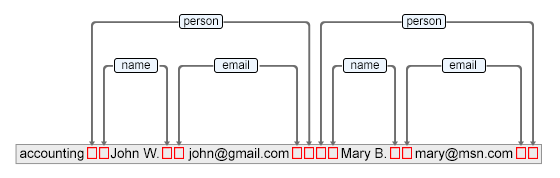
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
startOffset - Start offset, 0 based, inclusive.endOffset - End offset, 0 based, inclusive.
- Returns:
true if the delete operation was successful.
deleteNode
boolean deleteNode(AuthorNode node)
- Delete a node.
- Parameters:
node - The AuthorNode to delete.
- Returns:
true if the delete node operation was successful.
replaceRoot
void replaceRoot(AuthorDocumentFragment fragment)
- Replace the current root element with the new given one.
The fragment must contain only one element, otherwise the replacement will not be performed.
- Parameters:
fragment - The document fragment containing the new root element.
createDocumentFragment
AuthorDocumentFragment createDocumentFragment(int startOffset,
int endOffset)
throws javax.swing.text.BadLocationException
- Create an Author content fragment containing a clone of the document content for the
given range of offsets.
The offset ranges must be from the current AuthorDocument.
The Author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
startOffset - The start offset, 0 based, inclusive.endOffset - The end offset, 0 based, inclusive.
- Returns:
- A new
AuthorDocumentFragment.
It does not return a null fragment.
- Throws:
javax.swing.text.BadLocationException - When the offsets are not between 0 and the
content length, or the startOffset is greater than the endOffset.
createNewDocumentFragmentInContext
AuthorDocumentFragment createNewDocumentFragmentInContext(java.lang.String xmlFragment,
int contentOffset)
throws AuthorOperationException
- Create a new
AuthorDocumentFragment from an XML string in a specified context.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
xmlFragment - The XML Fragment.contentOffset - The offset where the XML fragment should be inserted.
This method doesn't perform any insertion. This parameter is used to
resolve entities and default attribute values from the DTD in the
specified XML fragment.
- Returns:
- The newly created
AuthorDocumentFragment.
It does not return a null fragment.
- Throws:
AuthorOperationException - If the new fragment creation fails.
createNewDocumentFragmentsInContext
AuthorDocumentFragment[] createNewDocumentFragmentsInContext(java.lang.String[] xmlFragments,
int[] contentOffsets)
throws AuthorOperationException
- Create an array of
AuthorDocumentFragment from an array of XML strings
in specified contexts.
This method should be used when multiple Author document fragments must be created.
In this situation the fragments are created faster than creating each of them by calling
createNewDocumentFragmentInContext(String, int) method.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
xmlFragments - The array of XML fragments.contentOffsets - The offsets where the XML fragments should be inserted.
The xml fragments and context offsets arrays must have the same size. The
nth offset corresponds to the nth xml fragment.
- Returns:
- The newly created
AuthorDocumentFragment.
It does not return a null fragment.
- Throws:
AuthorOperationException - If the xml fragments and context offsets sizes are different or
a fragment creation fails.- Since:
- 14
*********************************
EXPERIMENTAL - Subject to change
********************************
Please note that this API is not marked as final and it can change in one of the next versions of the application. If you have suggestions,
comments about it, please let us know.
createNewDocumentTextFragment
AuthorDocumentFragment createNewDocumentTextFragment(java.lang.String textFragment)
throws AuthorOperationException
- Create a new
AuthorDocumentFragment from an string.
- Parameters:
textFragment - The text fragment.
- Returns:
- The newly created
AuthorDocumentFragment holding the text node.
If the text fragment contains mark-up, it will be escaped.
It does not return a null fragment.
- Throws:
AuthorOperationException - If the new fragment creation fails.
serializeFragmentToXML
java.lang.String serializeFragmentToXML(AuthorDocumentFragment fragment)
throws javax.swing.text.BadLocationException
- Takes the given fragment and serializes it to XML text in the context
of the current document.
The following code example extracts the selection as an XML fragment,
processes and then reinserts it:
if(authorAccess.getEditorAccess().hasSelection()) {
AuthorDocumentController documentController = authorAccess.getDocumentController();
AuthorDocumentFragment selectionAsAFragment = documentController.createDocumentFragment(
authorAccess.getEditorAccess().getSelectionStart(), authorAccess.getEditorAccess().getSelectionEnd());
String selectionAsXML = documentController.serializeFragmentToXML(selectionAsAFragment);
//Deletes the selection
authorAccess.getEditorAccess().deleteSelection();
//Process the selectionAsXML fragment, modify it.
//................
//Insert the XML fragment back at caret position.
documentController.insertXMLFragment(selectionAsXML, authorAccess.getEditorAccess().getCaretOffset());
}
If the fragment contains change tracking highlights, they will be
serialized as processing instructions.
- Parameters:
fragment - The AuthorDocumentFragment to serialize.
- Returns:
- An equivalent
String representation of the given fragment.
It does not return a null String. If the fragment cannot be serialized
it will return an empty String.
- Throws:
javax.swing.text.BadLocationException - If the serialization could not be accomplished,
usually because the fragment was not properly built.
setAttribute
void setAttribute(java.lang.String attributeName,
AttrValue value,
AuthorElement element)
- Sets the value of an attribute in the specified element.
Attributes set in this manner (as opposed to calling
AuthorElement.setAttribute(String, AttrValue) directly)
will be subject to undo/redo.
- Parameters:
attributeName - Name of the attribute being changed.value - New AttrValue for the attribute. If null, the attribute is
removed from the element.element - The AuthorElement whose attribute is changing.
removeAttribute
void removeAttribute(java.lang.String attributeName,
AuthorElement element)
- Removes an attribute from the given element.
Attributes removed in this manner (as opposed to calling
AuthorElement.setAttribute(String, AttrValue) directly) will
be subject to undo/redo.
- Parameters:
attributeName - Name of the attribute to remove.element - The AuthorElement whose attribute will be removed.
getNodeAtOffset
AuthorNode getNodeAtOffset(int offset)
throws javax.swing.text.BadLocationException
- Returns the node at the given offset. The given offset must be
greater or equal to 0 and less than the current document length.
Note:
If the caret has the offset of an element's start offset marker character, it is considered to be before the element.
If the caret has the offset of an element's end offset marker character, it is considered to be inside the element.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
offset - The offset in the content, zero based.
- Returns:
- The
AuthorNode containing the offset,
or null when the actual document is null.
- Throws:
javax.swing.text.BadLocationException - When the offset is negative or greater
than the content length.
getContentInformationAtOffset
OffsetInformation getContentInformationAtOffset(int offset)
throws javax.swing.text.BadLocationException
- Returns content information for the offset.
If the offset is on a marker character the returned result will also contain the node which contains the range indicated by the marker.
- Parameters:
offset - The offset in the content, zero based.
- Returns:
- content information for the offset.
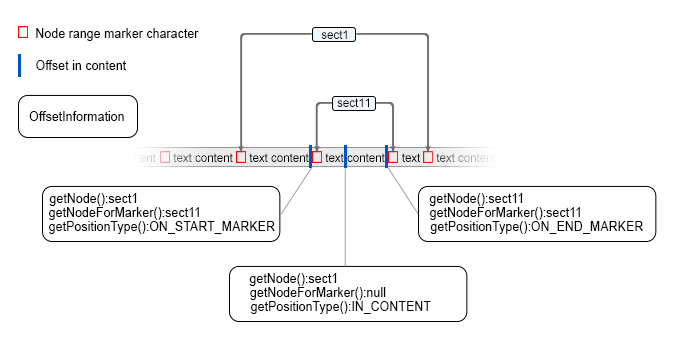
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Throws:
javax.swing.text.BadLocationException- Since:
- 12.2
createDocumentFragment
AuthorDocumentFragment createDocumentFragment(AuthorNode node,
boolean copyContent)
throws javax.swing.text.BadLocationException
- Create a document fragment containing a copy of the node. The node must be from the current AuthorDocument.
The attributes of the elements will be copied.
If
copyContent is true the node content
will be copied also.
- Parameters:
node - The AuthorNode to be duplicated.copyContent - If true the content of the node will
also be duplicated.
- Returns:
- The
AuthorDocumentFragment containing the duplicated node.
It does not return a null fragment.
- Throws:
javax.swing.text.BadLocationException - When the operation fails.
getText
@Deprecated
java.lang.String getText(int offset,
int length)
throws javax.swing.text.BadLocationException
- Deprecated. Use the API based on the
AuthorNode to get only the displayed text
without mark-up markers.
- Gets a sequence of text from the document text content.
The document text content can be obtained by adding all the text nodes
content.
The offset is considered to be relative to the
text content start offset. So the 0 offset corresponds to the offset of
the first valid char in the document.
The length represents also a number of valid chars encountered
after the real start offset was determined.
For the document:
[?PI?][article][!COMMENT][para]PARAGRAPH[/para][/article]
getText(0, 18) returns "PICOMMENTPARAGRAPH"
getText(5, 8) returns "MENTPARA"
- Parameters:
offset - The starting offset >= 0.length - The number of characters to retrieve >= 0
- Returns:
- The text
- Throws:
javax.swing.text.BadLocationException - The range given includes a position
that is not a valid position within the document text content.
getTextContentLength
@Deprecated
int getTextContentLength()
throws javax.swing.text.BadLocationException
- Deprecated. Use the API based on the
AuthorNode to get the length
of the displayed text only, without mark-up markers.
- Returns the length of the text content of the document. This is the number of valid
characters in the document text. The length
can be determined by the adding all text nodes content length.
For the document:
[?PI?][article][!COMMENT][para]PARAGRAPH[/para][/article]
The text content length will be:
"PI".length() + "COMMENT".length() + "PARAGRAPH".length()
2 + 7 + 9 = 18
- Returns:
- The text content length >= 0
- Throws:
javax.swing.text.BadLocationException
getUndoManager
javax.swing.undo.UndoManager getUndoManager()
- Get access to the Author undo manager.
- Returns:
- The Author undo manager. The returned undo manager cannot be
null.
beginCompoundEdit
void beginCompoundEdit()
- Begin a compound edit. This method should be called
to signal to the editing support that a complex editing operation begins.
The editing operations that occur between
beginCompoundEdit()
and endCompoundEdit() methods calls are regarded by the UndoManager
as a single operation which can be undone/redone in one step.
endCompoundEdit
void endCompoundEdit()
- End a compound edit. This method should be called
to signal to the editing support that a complex editing operation ends.
- See Also:
beginCompoundEdit()
cancelCompoundEdit
void cancelCompoundEdit()
- Cancel the current compound edit. This method should be called
to signal to the editing support that all edits performed so far inside a current compound edit must be undone.
The editing operations that occurred after the previous call to
beginCompoundEdit()
will be undo by the UndoManager.
- See Also:
beginCompoundEdit(),
endCompoundEdit()
insertText
void insertText(int offset,
java.lang.String text)
- Inserts a text at the given offset. After the operation the caret will be
positioned at the end of the inserted text.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
offset - The insert position, 0 based.text - The text to be inserted.
insertXMLFragment
void insertXMLFragment(java.lang.String xmlFragment,
int offset)
throws AuthorOperationException
- Insert an XML fragment at the given offset.
After the operation the caret will be positioned in the first leaf of the fragment.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
xmlFragment - The XML fragment to insert.offset - The insert position, 0 based.
- Throws:
AuthorOperationException - If the fragment could not be inserted.
insertXMLFragment
void insertXMLFragment(java.lang.String xmlFragment,
java.lang.String xpathLocation,
java.lang.String relativePosition)
throws AuthorOperationException
- Insert an XML fragment relative to the node identified by the
xpathLocation
and according with the relativePosition.
Note: if the xpathLocation is not specified then the XML fragment
will be inserted at caret position and the relativePosition will be ignored.
After the operation the caret will be positioned in the first leaf of the fragment.
- Parameters:
xmlFragment - The XML fragment.xpathLocation - The XPath location.relativePosition - The position relative to the node identified by the XPath location.
Can be one of the constants: AuthorConstants.POSITION_BEFORE, AuthorConstants.POSITION_AFTER,
AuthorConstants.POSITION_INSIDE_FIRST or AuthorConstants.POSITION_INSIDE_LAST.
- Throws:
AuthorOperationException - If the fragment could not be inserted.
insertXMLFragment
void insertXMLFragment(java.lang.String xmlFragment,
AuthorNode relativeTo,
java.lang.String relativePosition)
throws AuthorOperationException
- Insert an XML fragment relative to the given node and according with the
relativePosition.
After the operation the caret will be positioned at the end of the inserted XML fragment.
- Parameters:
xmlFragment - The XML fragment.relativeTo - The node to insert fragment relative to.relativePosition - The position relative to the node.
Can be one of the constants: AuthorConstants.POSITION_BEFORE, AuthorConstants.POSITION_AFTER,
AuthorConstants.POSITION_INSIDE_FIRST or AuthorConstants.POSITION_INSIDE_LAST.
- Throws:
AuthorOperationException - If the fragment could not be inserted.
insertXMLFragmentSchemaAware
SchemaAwareHandlerResult insertXMLFragmentSchemaAware(java.lang.String xmlFragment,
int offset)
throws AuthorOperationException
- Insert an XML fragment at the given offset in schema aware mode.
A normal insertion is executed when no schema is specified or schema aware feature is disable by the user
(see Preferences / Editor / Pages / Author / Schema aware).
If the fragments insertion is not allowed, a dialog will be shown proposing one of following solutions if they apply:
- insert the fragments inside a new element. The name of the element to wrap the fragments in is computed by analyzing the
left or right siblings.
By example, for the next Docbook situation:
<sect1>
<title>Section title</title>
{caret}
<para>para content</para>
</sect1>
if insert a fragment like: <emphasis>text</emphasis> the proposal is to
create a new para element and insert the fragment inside it. The proposal result will be:
<sect1>
<title>Section title</title>
<para><emphasis>text</emphasis></para>
<para>para content</para>
</sect1>
- split an ancestor of the node at insertion offset and insert the fragments between the resulted elements.
By example, for the next Docbook situation:
<sect1>
<title>Section title</title>
{caret}
<para>para content</para>
</sect1>
if insert a fragment like: <sect1>...section content...</sect1> the proposal is to
split the parent sect1 element and insert the fragment between the resulted sections. The proposal result will be:
<sect1>
<title>Section title</title>
</sect1>
<sect1>...section content...</sect1>
<sect1>
<para>para content</para>
</sect1>
- insert the fragments somewhere in the proximity of the insertion offset(left or right without skipping content).
By example, for the next Docbook situation:
<sect1>
<title>Section title</title>
{caret}
<para>para content</para>
</sect1>
if insert a fragment like: <emphasis>text</emphasis> the proposals are to
insert the fragment at the end of title or at beginning of para element.
- insert at offset the plain text resulted after removing the mark-up.
By example, for the next Docbook situation:
<sect1>
<title>Section title {caret}</title>
</sect1>
if insert a fragment like: <para>fragment <emphasis>content</emphasis></para>
the proposal is to remove the fragment mark-up and insert the text 'fragment content' at caret position.
The proposal result will be:
<sect1>
<title>Section title fragment content</title>
</sect1>
- insert the fragments at insertion offset, even they are not allowed.
If the developer specifies an AuthorSchemaAwareEditingHandler then this handler has priority
for executing the insert operation.
- Parameters:
xmlFragment - The XML fragment to insert.offset - The insert position, 0 based.
- Returns:
- The result of the schema aware insertion.
Can be used to get the insertion offset for the given fragments.
- Throws:
AuthorOperationException - If the fragment could not be inserted.
insertXMLFragmentSchemaAware
SchemaAwareHandlerResult insertXMLFragmentSchemaAware(java.lang.String xmlFragment,
int offset,
boolean replaceSelection)
throws AuthorOperationException
- Insert an XML fragment at the given offset in schema aware mode.
A normal insertion is executed when no schema is specified or schema aware feature is disable by the user
(see Preferences / Editor / Pages / Author / Schema aware).
If the fragments insertion is not allowed, a dialog will be shown proposing one of following solutions if they apply:
- insert the fragments inside a new element. The name of the element to wrap the fragments in is computed by analyzing the
left or right siblings.
By example, for the next Docbook situation:
<sect1>
<title>Section title</title>
{caret}
<para>para content</para>
</sect1>
if insert a fragment like: <emphasis>text</emphasis> the proposal is to
create a new para element and insert the fragment inside it. The proposal result will be:
<sect1>
<title>Section title</title>
<para><emphasis>text</emphasis></para>
<para>para content</para>
</sect1>
- split an ancestor of the node at insertion offset and insert the fragments between the resulted elements.
By example, for the next Docbook situation:
<sect1>
<title>Section title</title>
{caret}
<para>para content</para>
</sect1>
if insert a fragment like: <sect1>...section content...</sect1> the proposal is to
split the parent sect1 element and insert the fragment between the resulted sections. The proposal result will be:
<sect1>
<title>Section title</title>
</sect1>
<sect1>...section content...</sect1>
<sect1>
<para>para content</para>
</sect1>
- insert the fragments somewhere in the proximity of the insertion offset(left or right without skipping content).
By example, for the next Docbook situation:
<sect1>
<title>Section title</title>
{caret}
<para>para content</para>
</sect1>
if insert a fragment like: <emphasis>text</emphasis> the proposals are to
insert the fragment at the end of title or at beginning of para element.
- insert at offset the plain text resulted after removing the mark-up.
By example, for the next Docbook situation:
<sect1>
<title>Section title {caret}</title>
</sect1>
if insert a fragment like: <para>fragment <emphasis>content</emphasis></para>
the proposal is to remove the fragment mark-up and insert the text 'fragment content' at caret position.
The proposal result will be:
<sect1>
<title>Section title fragment content</title>
</sect1>
- insert the fragments at insertion offset, even they are not allowed.
If the developer specifies an AuthorSchemaAwareEditingHandler then this handler has priority
for executing the insert operation.
- Parameters:
xmlFragment - The XML fragment to insert.offset - The insert position, 0 based.replaceSelection - true to replace the selected Author content with the fragment,
false to leave the selected content and paste at caret position.
- Returns:
- The result of the schema aware insertion.
Can be used to get the insertion offset for the given fragments.
- Throws:
AuthorOperationException - If the fragment could not be inserted.
insertFragment
void insertFragment(int insertOffset,
AuthorDocumentFragment frag)
- Insert an
AuthorDocumentFragment at the given offset.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
insertOffset - The offset where the fragment will be inserted, 0 based.frag - The AuthorDocumentFragment to be inserted.
processContentRange
boolean processContentRange(int startOffset,
int endOffset,
RangeProcessor rangeProcessor)
throws javax.swing.text.BadLocationException,
AuthorOperationException
- This method is useful if you want to make text processing on a given Author selection.
You will receive a call back which will give you the AuthorDocumentFragment to process.
When finished, the range will be replaced with the processed fragment.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset().
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
startOffset - Start offset of the processed range (inclusive).endOffset - End offset of the processed range (inclusive).rangeProcessor - The range processor which gets notified to process the
AuthorDocumentFragment.
- Returns:
true if the modifications were merged back in the Author content.
For example when the selection cannot be replaced (inside a not-editable element) this method
can return false.
- Throws:
javax.swing.text.BadLocationException
AuthorOperationException- Since:
- 12.2
insertFragmentSchemaAware
SchemaAwareHandlerResult insertFragmentSchemaAware(int insertOffset,
AuthorDocumentFragment frag)
throws AuthorOperationException
- Insert an
AuthorDocumentFragment at the given offset in schema aware mode.
A normal insertion is executed when no schema is specified or schema aware feature is disable by the user
(see Preferences / Editor / Pages / Author / Schema aware).
For more details about schema aware solutions see comments from insertXMLFragmentSchemaAware(String, int) method.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
insertOffset - The offset where the fragment will be inserted, 0 based.frag - The AuthorDocumentFragment to be inserted.
- Returns:
- The result of the schema aware insertion.
- Throws:
AuthorOperationException - If the fragment could not be inserted.
surroundInFragment
void surroundInFragment(java.lang.String xmlFragment,
int startOffset,
int endOffset)
throws AuthorOperationException
- Surround the content between the given offsets with the
xmlFragment.
If endOffset < startOffset the xmlFragment
will be inserted at startOffset.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
xmlFragment - The XML fragment which will surround the given interval.
The first leaf node of the XML fragment will be the parent of the surrounded content.startOffset - The start offset of the content to be surrounded, 0 based and inclusive.endOffset - The end offset of the content to be surrounded, 0 based and inclusive.
- Throws:
AuthorOperationException - If the content between start and end offset could not be surrounded.
surroundInFragment
void surroundInFragment(AuthorDocumentFragment xmlFragment,
int startOffset,
int endOffset)
throws AuthorOperationException
- Surround the content between the given offsets with the
xmlFragment.
If endOffset < startOffset the xmlFragment
will be inserted at startOffset.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
xmlFragment - The XML fragment which will surround the given interval.
The first leaf node of the XML fragment will be the parent of the surrounded content.startOffset - The start offset of the content to be surrounded, 0 based and inclusive.endOffset - The end offset of the content to be surrounded, 0 based and inclusive.
- Throws:
AuthorOperationException - If the content between start and end offset could not be surrounded.- Since:
- 12.1
surroundInText
void surroundInText(java.lang.String header,
java.lang.String footer,
int startOffset,
int endOffset)
throws AuthorOperationException
- Surround the content between the given offsets with plain text fragments(without XML parsing).
The method inserts the
header at startOffset and
the footer at endOffset.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
header - The header to be inserted before the surrounded text.footer - The footer to be inserted after the surrounded text.startOffset - The start offset of the text to be surrounded, 0 based.endOffset - The end offset of the text to be surrounded, 0 based.
- Throws:
AuthorOperationException - If the operation failed.
inInlineContext
boolean inInlineContext(int offset)
throws javax.swing.text.BadLocationException,
AuthorOperationException
- Test if the context at the given
offset is inline or not.
For example a text paragraph determines an inline context,
and for an offset inside this paragraph the method will return true.
For an offset between two paragraphs (considered to be block level)
the method will return false.
- Parameters:
offset - The offset in the document, zero based.
- Returns:
- Returns
true if the given offset is inside an inline context.
false otherwise.
- Throws:
javax.swing.text.BadLocationException - When the offset does not exists in the document content.
AuthorOperationException - If the operation failed.
addAuthorListener
void addAuthorListener(AuthorListener listener)
- Add an Author listener to be notified about changes regarding the document
and the document structure.
- Parameters:
listener - The AuthorListener to be added.
addAuthorPersistentHighlightListener
void addAuthorPersistentHighlightListener(AuthorPersistentHighlightsListener listener)
- Adds a listener to be notified about changes regarding the persistent
highlights. In the persistent highlights are included:
- Parameters:
listener - The listener- Since:
- 14
*********************************
EXPERIMENTAL - Subject to change
********************************
Please note that this API is not marked as final and it can change in one of the next versions of the application. If you have suggestions,
comments about it, please let us know.
- See Also:
AuthorPersistentHighlight.PersistentHighlightType,
AuthorPersistentHighlight
removeAuthorPersistentHighlightListener
void removeAuthorPersistentHighlightListener(AuthorPersistentHighlightsListener listener)
- Removes a persistent highlights listener.
- Parameters:
listener - The listener to remove.- Since:
- 14
*********************************
EXPERIMENTAL - Subject to change
********************************
Please note that this API is not marked as final and it can change in one of the next versions of the application. If you have suggestions,
comments about it, please let us know.
removeAuthorListener
void removeAuthorListener(AuthorListener listener)
- Remove an Author listener.
- Parameters:
listener - The AuthorListener to be removed.
evaluateXPath
java.lang.Object[] evaluateXPath(java.lang.String xpathExpression,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments,
boolean processChangeMarkers)
throws AuthorOperationException
- Evaluates an XPath expression.
This function returns the result of the given XPath expression as an array of
Object.
Author DOM text nodes, DOM CDATA sections and DOM comment wrappers can be
ignored for performance reasons.
For example, executing the expression:
//node()
will return an array with all the Author DOM Node wrappers in the document.
while evaluating the expression:
count(//node())
will return an array having a single component representing the number of nodes in the document.
Evaluating the expression:
//node(), count(//node())
will return an array containing all the Author DOM Node wrappers in the document and having as last component
the total number of nodes.
- Parameters:
xpathExpression - The XPath expression. If the XPath expression is relative, it will be computed in the context of the current caret position.ignoreTexts - If true DOM text nodes will not be returned.ignoreCData - If true DOM CDATA sections will not be returned.ignoreComments - If true DOM comments will not be returned.processChangeMarkers - If false the change markers (inserts/deletes/comments) will be ignored
and the XPath will return results as if the insert changes are accepted, the delete changes are rejected and the comment changes are ignored.
If true the XPath will be applied over the document as if the change markers are applied.
(All changes processed to processing instructions like when the XML document gets saved on disk).
- Returns:
- An array of objects representing the XPath result.
It does not return a
null array. If the XPath evaluation fails it will return
an empty array.
- Throws:
AuthorOperationException - If the XPath expression failed to be evaluated.
evaluateXPath
java.lang.Object[] evaluateXPath(java.lang.String xpathExpression,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments)
throws AuthorOperationException
- Evaluates an XPath expression.
This function returns the result of the given XPath expression as an array of
Object.
Author DOM text nodes, DOM CDATA sections and DOM comment wrappers can be
ignored for performance reasons.
For example, executing the expression:
//node()
will return an array with all the Author DOM Node wrappers in the document.
while evaluating the expression:
count(//node())
will return an array having a single component representing the number of nodes in the document.
Evaluating the expression:
//node(), count(//node())
will return an array containing all the Author DOM Node wrappers in the document and having as last component
the total number of nodes.
If change tracking (insert/remove/comment) markers exist in the document they will be ignored
and the XPath will return results as if the insert changes are accepted, the delete changes are rejected and the comment changes are ignored.
- Parameters:
xpathExpression - The XPath expression. If the XPath expression is relative, it will be computed in the context of the current caret position.ignoreTexts - If true DOM text nodes will not be returned.ignoreCData - If true DOM CDATA sections will not be returned.ignoreComments - If true DOM comments will not be returned.
- Returns:
- An array of objects representing the XPath result.
It does not return a
null array. If the XPath evaluation fails it will return
an empty array.
- Throws:
AuthorOperationException - If the XPath expression failed to be evaluated.
findNodesByXPath
AuthorNode[] findNodesByXPath(java.lang.String xpathExpression,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments,
boolean processChangeMarkers)
throws AuthorOperationException
- Finds the author nodes selected by the given XPath expression.
The result of this function is an array of
AuthorNode selected
by the given XPath expression.
Author text nodes, Author CDATA section nodes and Author comment nodes
can be ignored for performance reasons.
For example executing the expression:
//node()
will return an array with all the AuthorNode's in the document.
But the result of calling the function with the expression:
count(//node())
will return an empty array.
If change tracking (insert/remove/comment) markers exist in the document they will be ignored
and the XPath will return results as if the insert changes are accepted, the delete changes are rejected and the comment changes are ignored.
- Parameters:
xpathExpression - The XPath expression.ignoreTexts - If true Author text nodes will not be returned.ignoreCData - If true Author CDATA sections will not be returned.ignoreComments - If true Author comments will not be returned.processChangeMarkers - If false the change markers (inserts/deletes/comments) will be ignored
and the XPath will return results as if the insert changes are accepted, the delete changes are rejected and the comment changes are ignored.
If true the XPath will be applied over the document as if the change markers are applied.
(All changes processed to processing instructions like when the XML document gets saved on disk).
- Returns:
- The Author nodes selected by the XPath expression.
It does not return a
null array of nodes.
If the evaluation of the XPath expression fails it will return an empty array.
- Throws:
AuthorOperationException - If the XPath expression failed to be evaluated.
findNodesByXPath
AuthorNode[] findNodesByXPath(java.lang.String xpathExpression,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments)
throws AuthorOperationException
- Finds the author nodes selected by the given XPath expression.
The result of this function is an array of
AuthorNode selected
by the given XPath expression.
Author text nodes, Author CDATA section nodes and Author comment nodes
can be ignored for performance reasons.
For example executing the expression:
//node()
will return an array with all the AuthorNode's in the document.
But the result of calling the function with the expression:
count(//node())
will return an empty array.
If change tracking (insert/remove/comment) markers exist in the document the XPath will be applied over the document as if the change tracking is applied
(All changes processed to processing instructions like when the XML document gets saved on disk).
- Parameters:
xpathExpression - The XPath expression. If the XPath expression is relative, it will be computed in the context of the current caret position.ignoreTexts - If true Author text nodes will not be returned.ignoreCData - If true Author CDATA sections will not be returned.ignoreComments - If true Author comments will not be returned.
- Returns:
- The Author nodes selected by the XPath expression.
It does not return a
null array of nodes.
If the evaluation of the XPath expression fails it will return an empty array.
- Throws:
AuthorOperationException - If the XPath expression failed to be evaluated.
getXPathLocationOffset
int getXPathLocationOffset(java.lang.String xpathLocation,
java.lang.String relativePosition)
throws AuthorOperationException
- Compute the document offset defined by the XPath location and relative position.
- Parameters:
xpathLocation - The XPath defining a node in document.relativePosition - The relative position to the node.
One of the following: AuthorConstants.POSITION_BEFORE,
AuthorConstants.POSITION_INSIDE_FIRST, AuthorConstants.POSITION_INSIDE_LAST or
AuthorConstants.POSITION_AFTER
- Returns:
- The offset in document.
- Throws:
AuthorOperationException - If it fails.
insertMultipleElements
void insertMultipleElements(AuthorElement parentElement,
java.lang.String[] elementNames,
int[] offsets,
java.lang.String namespace)
- Insert multiple elements at the given offsets.
Note: The offsets and elements must be in document order.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
parentElement - The parent element that contains all the new inserted
elements.elementNames - The element names to be inserted.offsets - The absolute offsets where the elements will be inserted.namespace - The namespace of the new inserted elements.
insertMultipleFragments
boolean insertMultipleFragments(AuthorElement parentElement,
AuthorDocumentFragment[] fragments,
int[] offsets)
- Insert multiple fragments at the given offsets.
Note: The offsets and fragments must be in document order.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
parentElement - The parent element that contains all the new inserted
elements.fragments - The fragments to be inserted.offsets - The absolute offsets where the fragments will be inserted.
- Returns:
true if the operation succeed.- Since:
- 14
*********************************
EXPERIMENTAL - Subject to change
********************************
Please note that this API is not marked as final and it can change in one of the next versions of the application. If you have suggestions,
comments about it, please let us know.
multipleDelete
void multipleDelete(AuthorElement parentElement,
int[] startOffsets,
int[] endOffsets)
- Deletes the given intervals.
Note: The offsets must be in document order and the intervals must not
intersect with each other.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
parentElement - The element that contains all the deleted intervals.startOffsets - The start offset for each interval.
Must be in document order.endOffsets - The end offset for each interval.
Must be in document order.
setDoctype
void setDoctype(AuthorDocumentType docType)
- Set a new internal document type to the Author content.
This is a good method to add new entities (regular or unparsed) to the internal document type of the document.
WARNING: if these modifications affect regular entities already inserted and expanded,
they will not be re-parsed and their old content will remain rendered as such.
- Parameters:
docType - The document type information.
getDoctype
AuthorDocumentType getDoctype()
- Returns information about the internal associated document type.
- Returns:
- The internal associated document type information.
If the document does not have an internal Doctype section
the method will return
null.
getCommonParentNode
AuthorNode getCommonParentNode(AuthorDocument doc,
int startOffset,
int endOffset)
throws javax.swing.text.BadLocationException
- Find the common ancestor node of the two offsets.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The image represents part of the document content and red markers represent special control
characters which represent the node ranges.
- Parameters:
doc - The author document.startOffset - The start offset.endOffset - The end offset.
- Returns:
- The common ancestor. Can be the document but it cannot be
null.
- Throws:
javax.swing.text.BadLocationException
getAuthorDocumentNode
AuthorDocument getAuthorDocumentNode()
- Returns the edited author document.
- Returns:
- The author document. The document cannot be
null.
setDocumentFilter
void setDocumentFilter(AuthorDocumentFilter authorDocumentFilter)
- Sets the
AuthorDocumentFilter to be used for altering the document edits.
- Parameters:
authorDocumentFilter - The AuthorDocumentFilter to be used.
getChars
void getChars(int where,
int len,
javax.swing.text.Segment chars)
throws javax.swing.text.BadLocationException
- The content represents the entire text content of the Author page + additional markers/sentinels
at offsets which are pointed to by the AuthorNodes.
Each AuthorNode points to specific start and end character markers in the content.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
Retrieves a portion of the content into the specified Segment.
- Parameters:
where - The starting position >= 0, where + len <= length()len - The number of characters to be retrieved >= 0chars - The Segment object to return the characters int.o
- Throws:
javax.swing.text.BadLocationException - If the specified position or length are invalid.
getFilteredContent
AuthorFilteredContent getFilteredContent(int start,
int end,
AuthorNodesFilter nodesFilter)
- Retrieves the content between the given start and end offset, excluding the
content of the invisible nodes (that have display none style property), the
content deleted with track changes, the sentinels of inline elements and the
content of filtered nodes.
The filtered nodes are the nodes for which
AuthorNodesFilter.shouldFilterNode(AuthorNode) returns true.
The content represents the entire text content of the Author page + additional markers/sentinels
at offsets which are pointed to by the AuthorNodes.
Each AuthorNode points to specific start and end character markers in the content.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
Retrieves the content from start to end offsets,
- Parameters:
start - The starting position >= 0.end - The end position >= 0, inclusivenodesFilter - Provides information about the Author nodes that should be filtered.
- Returns:
- The char sequence representing the filtered Author content.
- Since:
- 12.1
getAuthorSchemaManager
AuthorSchemaManager getAuthorSchemaManager()
- Returns:
- The schema manager associated with this document. Null value is returned if there is no schema associated.
insertXMLFragmentSchemaAware
SchemaAwareHandlerResult insertXMLFragmentSchemaAware(java.lang.String xmlFragment,
java.lang.String xpathLocation,
java.lang.String relativePosition)
throws AuthorOperationException
- Insert an XML fragment relative to the node identified by the
xpathLocation
and according with the relativePosition.
Note: if the xpathLocation is not specified then the XML fragment
will be inserted at caret position and the relativePosition will be ignored.
For more details about schema aware solutions see comments from insertXMLFragmentSchemaAware(String, int) method.
- Parameters:
xmlFragment - The XML fragment.xpathLocation - The XPath location.relativePosition - The position relative to the node identified by the XPath location.
Can be one of the constants: AuthorConstants.POSITION_BEFORE, AuthorConstants.POSITION_AFTER,
AuthorConstants.POSITION_INSIDE_FIRST or AuthorConstants.POSITION_INSIDE_LAST.
- Returns:
- The result of the schema aware insertion.
- Throws:
AuthorOperationException - If the fragment could not be inserted.- See Also:
insertXMLFragmentSchemaAware(String, int)
isEditable
boolean isEditable(AuthorNode node)
- Test if a node is editable or not. A node is not editable for one of the following cases:
- the CSS property 'editable' is to 'false';
- the node is entirely included into a DELETED change marker.
- Parameters:
node - The node to test if is editable.
- Returns:
- True if the node is editable, false otherwise.
renameElement
void renameElement(AuthorElement contextNode,
java.lang.String newName)
- Rename an Author Element, set another qualified name to it.
- Parameters:
contextNode - The element to rename.newName - The new qualified name to set to it.- Since:
- 12.1
getTextContentIterator
TextContentIterator getTextContentIterator(int startOffset,
int endOffset)
- Get an iterator over the text content between two offsets.
- Parameters:
startOffset - Start offset, 0 based, inclusive.endOffset - End offset, 0 based, inclusive.
- Returns:
- The text content iterator
- Since:
- 13
createPositionInContent
javax.swing.text.Position createPositionInContent(int offset)
throws javax.swing.text.BadLocationException
- Create a flexible position in the Author Content. The position is updated automatically when modifications occur before it.
It behaves exactly like a
Position added to a swing Document.
- Parameters:
offset - The offset where to create the position
- Returns:
- The created position.
- Throws:
javax.swing.text.BadLocationException- Since:
- 13
addClipboardFragmentProcessor
void addClipboardFragmentProcessor(ClipboardFragmentProcessor clipboardFragmentProcessor)
- Add a processor which can analyze and modify
AuthorDocumentFragment objects before they are inserted in the Author.
The processor specified in the ExtensionsBundle will have maximum priority.
- Parameters:
clipboardFragmentProcessor - a processor which can analyze and modify AuthorDocumentFragment objects before they are inserted in the Author.- Since:
- 13
removeClipboardFragmentProcessor
void removeClipboardFragmentProcessor(ClipboardFragmentProcessor clipboardFragmentProcessor)
- Remove a processor which can analyze and modify
AuthorDocumentFragment objects before they are inserted in the Author.
- Parameters:
clipboardFragmentProcessor - a processor which can analyze and modify AuthorDocumentFragment objects before they are inserted in the Author.- Since:
- 13
addUniqueAttributesProcessor
void addUniqueAttributesProcessor(UniqueAttributesProcessor uniqueAttributesProcessor)
- Add a processor which is asked to automatically generate unique IDs after content has been inserted in the Author.
The processor can also specify which attributes can be copied on split.
The
UniqueAttributesRecognizer specified in the ExtensionsBundle will have maximum priority.
- Parameters:
uniqueAttributesProcessor - a processor which is asked to automatically generate unique IDs after content has been inserted in the Author.
The processor can also specify which attributes can be copied on split.- Since:
- 13
removeUniqueAttributesProcessor
void removeUniqueAttributesProcessor(UniqueAttributesProcessor uniqueAttributesProcessor)
- Remove a processor which is asked to automatically generate unique IDs after content has been inserted in the Author.
The processor can also specify which attributes can be copied on split.
The
UniqueAttributesRecognizer specified in the ExtensionsBundle will have maximum priority.
- Parameters:
uniqueAttributesProcessor - a processor which is asked to automatically generate unique IDs after content has been inserted in the Author.
The processor can also specify which attributes can be copied on split.- Since:
- 13
findNodesByXPath
AuthorNode[] findNodesByXPath(java.lang.String xpathExpression,
AuthorNode contextNode,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments,
boolean processChangeMarkers)
throws AuthorOperationException
- Finds the author nodes selected by the given XPath expression.
The result of this function is an array of
AuthorNode selected
by the given XPath expression.
Author text nodes, Author CDATA section nodes and Author comment nodes
can be ignored for performance reasons.
For example executing the expression:
//node()
will return an array with all the AuthorNode's in the document.
But the result of calling the function with the expression:
count(//node())
will return an empty array.
If change tracking (insert/remove/comment) markers exist in the document they will be ignored
and the XPath will return results as if the insert changes are accepted, the delete changes are rejected and the comment changes are ignored.
- Parameters:
xpathExpression - The XPath expression. If the XPath expression is relative, it will be computed in the context of the current caret position.contextNode - The node in the context of which the relative XPath Expressions will computed.
If null the context node will be the node at the current caret position.ignoreTexts - If true Author text nodes will not be returned.ignoreCData - If true Author CDATA sections will not be returned.ignoreComments - If true Author comments will not be returned.processChangeMarkers - If false the change markers (inserts/deletes/comments) will be ignored
and the XPath will return results as if the insert changes are accepted, the delete changes are rejected and the comment changes are ignored.
If true the XPath will be applied over the document as if the change markers are applied.
(All changes processed to processing instructions like when the XML document gets saved on disk).
- Returns:
- The Author nodes selected by the XPath expression.
It does not return a
null array of nodes.
If the evaluation of the XPath expression fails it will return an empty array.
- Throws:
AuthorOperationException - If the XPath expression failed to be evaluated.- Since:
- 13
evaluateXPath
java.lang.Object[] evaluateXPath(java.lang.String xpathExpression,
AuthorNode contextNode,
boolean ignoreTexts,
boolean ignoreCData,
boolean ignoreComments,
boolean processChangeMarkers)
throws AuthorOperationException
- Evaluates an XPath expression.
This function returns the result of the given XPath expression as an array of
Object.
Author DOM text nodes, DOM CDATA sections and DOM comment wrappers can be
ignored for performance reasons.
For example, executing the expression:
//node()
will return an array with all the Author DOM Node wrappers in the document.
while evaluating the expression:
count(//node())
will return an array having a single component representing the number of nodes in the document.
Evaluating the expression:
//node(), count(//node())
will return an array containing all the Author DOM Node wrappers in the document and having as last component
the total number of nodes.
- Parameters:
xpathExpression - The XPath expression. If the XPath expression is relative, it will be computed in the context of the context node.contextNode - The node in the context of which the relative XPath Expressions will computed.
If null the context node will be the node at the current caret position.ignoreTexts - If true DOM text nodes will not be returned.ignoreCData - If true DOM CDATA sections will not be returned.ignoreComments - If true DOM comments will not be returned.processChangeMarkers - If false the change markers (inserts/deletes/comments) will be ignored
and the XPath will return results as if the insert changes are accepted, the delete changes are rejected and the comment changes are ignored.
If true the XPath will be applied over the document as if the change markers are applied.
(All changes processed to processing instructions like when the XML document gets saved on disk).
- Returns:
- An array of objects representing the XPath result.
It does not return a
null array. If the XPath evaluation fails it will return
an empty array.
- Throws:
AuthorOperationException - If the XPath expression failed to be evaluated.- Since:
- 13
unwrapDocumentFragment
AuthorDocumentFragment unwrapDocumentFragment(AuthorDocumentFragment fragmentToUnwrap)
throws javax.swing.text.BadLocationException
- Unwrap a given Author document fragment. If the given fragment has a root
element, this method returns a fragment containing the content of the root
(or
null if the root is empty), else the given fragment is returned.
The author content contains the entire XML document text and special marker characters.
Each author node points in the content to the start and end marker characters which are used to
delimit it's range.
The start and end offsets pointed to by the AuthorNode can be retrieved using the
AuthorNode.getStartOffset() and AuthorNode.getEndOffset()
The following image represents the architecture of an Author document fragment that is a part
of the document content. The red markers represent special control characters which
represent the node ranges:
- Parameters:
fragmentToUnwrap - The Author document fragment to be unwrapped.
- Returns:
- The content of the fragment root (
null if the root is empty) or the given fragment.
- Throws:
javax.swing.text.BadLocationException - When the offsets are not between 0 and the
content length, or the startOffset is greater than the endOffset.- Since:
- 14
*********************************
EXPERIMENTAL - Subject to change
********************************
Please note that this API is not marked as final and it can change in one of the next versions of the application. If you have suggestions,
comments about it, please let us know.
getUnparsedEntityUri
java.lang.String getUnparsedEntityUri(AuthorNode contextNode,
java.lang.String entityName)
- Returns the URI of the unparsed entity with the specified name, in the
same document as the context node.
- Parameters:
contextNode - Context node.entityName - Unparsed entity name.
- Returns:
- The URI of the entity or
null if the entity is undefined. - Since:
- 14.2
*********************************
EXPERIMENTAL - Subject to change
********************************
Please note that this API is not marked as final and it can change in one of the next versions of the application. If you have suggestions,
comments about it, please let us know.
© Copyright SyncRO Soft SRL 2002 - 2013. All rights reserved.